


LLMs are no longer just a playground experiment. If you’ve recently worked on any production system involving language models, you know they’ve moved deep into backend automation. They're parsing emails, generating support tickets, creating product descriptions, returning summaries, and sometimes calling your APIs.
And here’s where things start breaking quietly.
An API has strict rules. It expects a request body to follow a defined structure. LLMs, on the other hand, are language models. They generate text. They try to guess what looks right. You can prompt them to return JSON, add system instructions, and use tools like function calling, but the output can fail in subtle, painful ways.
If your endpoint expects a string category field, but the model returns an integer, it breaks. If a required field is missing, it breaks. If the model adds confidence_score: 0.91 to an object never designed to hold it, it may silently pollute your data.
Need real-time insight into how your APIs are used and performing?
Treblle helps you monitor, debug, and optimize every API request.
Explore Treblle
You’re working with APIs, not natural language processors. Your backend expects structure. LLMs don’t guarantee it. It doesn’t raise red flags like a 500 error when something breaks here. It can sit quietly in your logs or, worse, pass through and cause issues downstream in your database, analytics, or user interface.
Now, let’s look at how that plays out.
Language models guess the next word. Their training doesn’t focus on following schemas. Even when you add guardrails like system prompts, retries, and response formatting tools, you still deal with a system that makes probabilistic decisions.
Let's examine a concrete example.
You're building a content moderation system where an LLM analyzes user posts and returns structured data about potential policy violations. Your API expects this exact format:
{
"violation_detected": true,
"severity": "medium",
"categories": ["spam", "harassment"],
"confidence_score": 0.85,
"recommended_action": "flag_for_review"
}
Your prompt engineering is solid. You provided clear instructions and examples, and even specified the JSON schema. During testing, everything works flawlessly. But in production, you start seeing responses like this:
{
"violation_detected": true,
"severity": "MEDIUM",
"categories": ["spam", "harassment", "potentially offensive language"],
"confidence_score": "85%",
"recommended_action": "flag_for_review",
"explanation": "This post contains elements that suggest spam behavior..."
}
Notice the problems:
severity is in uppercase instead of lowercase, confidence_score is a string with a percentage symbol instead of a float, an unexpected category value, and an entirely new explanation field appears. These deviations can break downstream systems that expect strict data types and field names.
Now, we will see why traditional testing falls short.
You can't test every possible variation an LLM might produce. Unlike deterministic APIs that always return the same structure, LLMs introduce variability that makes comprehensive testing impossible. You might test 1,000 scenarios successfully, only to have the 1,001st break your production system.
API contracts, implemented through specifications like OpenAPI or JSON Schema, define precisely what your API endpoints should accept and return. They act as gatekeepers, ensuring every request and response conforms to your defined structure before reaching your application logic.
When you implement a contract for our content moderation example, you specify that:
The severity must be one of three lowercase strings: "low," "medium," or "high."
You define confidence_score as a number between 0 and 1.
You restrict categories to a predefined list of valid policy categories.
Any response that doesn't match these specifications gets rejected immediately.
This approach solves several critical problems.
First, it provides consistency. Regardless of how your LLM decides to phrase its response, your downstream systems always receive data in the expected format.
Second, it enables faster debugging. Instead of tracking down why your user authentication broke three layers deep in your application, you catch the malformed response at the API boundary.
Third, it facilitates collaboration between LLM teams and those building the systems that consume their outputs.
Now we’ll look at how Treblle strengthens that contract enforcement in production.
If you connect your API to Treblle, it automatically picks up your OpenAPI schema and starts validating every request and response against that spec.
And it doesn’t just throw errors. Treblle logs, analyzes, and flags issues that matter:
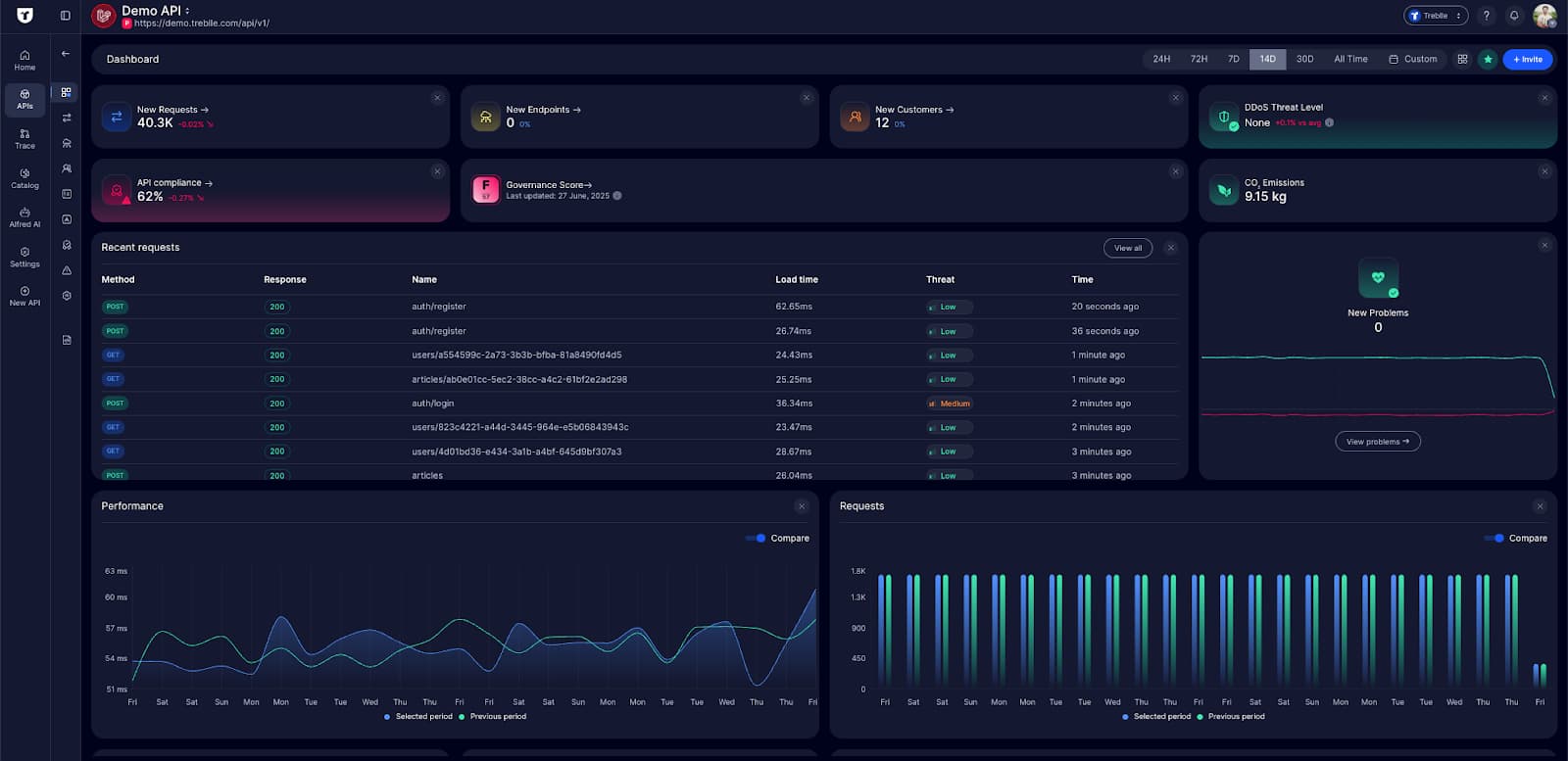
Payload structure mismatches
Missing or unexpected fields
Incorrect types or malformed responses
Extra fields hallucinated by the model
Each violation is logged in detail to see precisely what broke and why.
If you’re actively working with LLMs in production, validating contracts is only one part of the puzzle. You also need to understand how AI outputs behave over time — where they break, why they break, and what patterns emerge. This guide on testing AI APIs with API Insights breaks down how to uncover these issues and use observability to improve stability.
And this works without additional instrumentation. You don’t need to add middleware or write custom validators. Treblle hooks into your API traffic and starts applying the contract checks out of the box.
Tracks patterns of repeated violations, like a model always omitting a specific field
Logs complete request and response with over 50+ metadata points
Surfaces contract and drift over time, so you know when your API or model starts changing subtly.
Scores your endpoints for AI-readiness, helping you spot schema weaknesses (like vague or missing type definitions) before they cause problems downstream
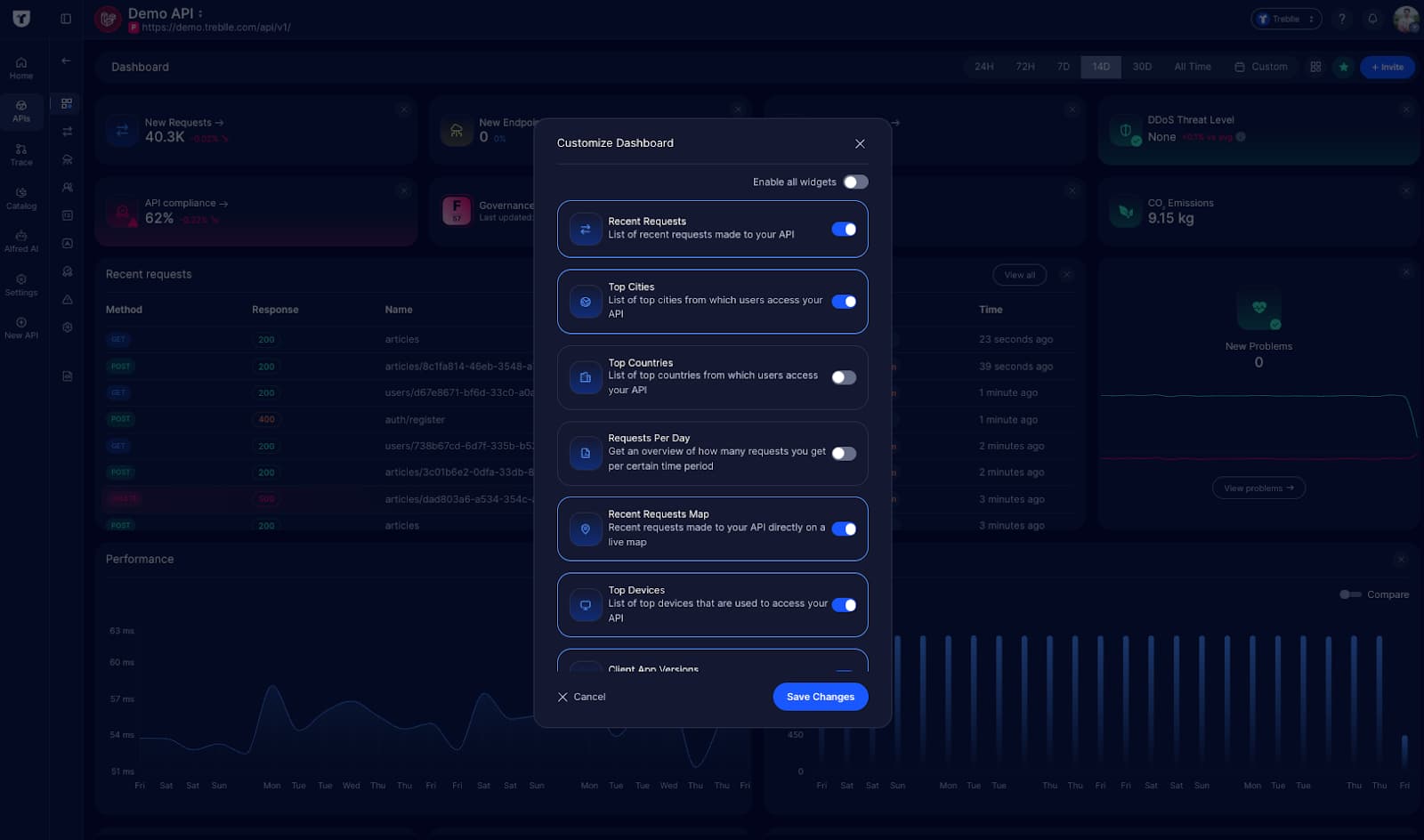
This makes Treblle more than just a schema checker. It becomes your real-time enforcement engine, catching and documenting model output issues before they affect your systems.
LLM behavior changes over time.
Maybe you fine-tune.
Maybe you switch models.
Maybe just a change in prompt phrasing makes a difference.
You can’t assume consistency; you need to measure it.
Treblle gives you visibility into how your LLM outputs interact with your APIs and whether those interactions are holding up.
Which endpoints are seeing the most schema violations
What types of fields are most commonly missing
Which LLM payloads are drifting from expected formats
How does your response quality and structure hold up over time
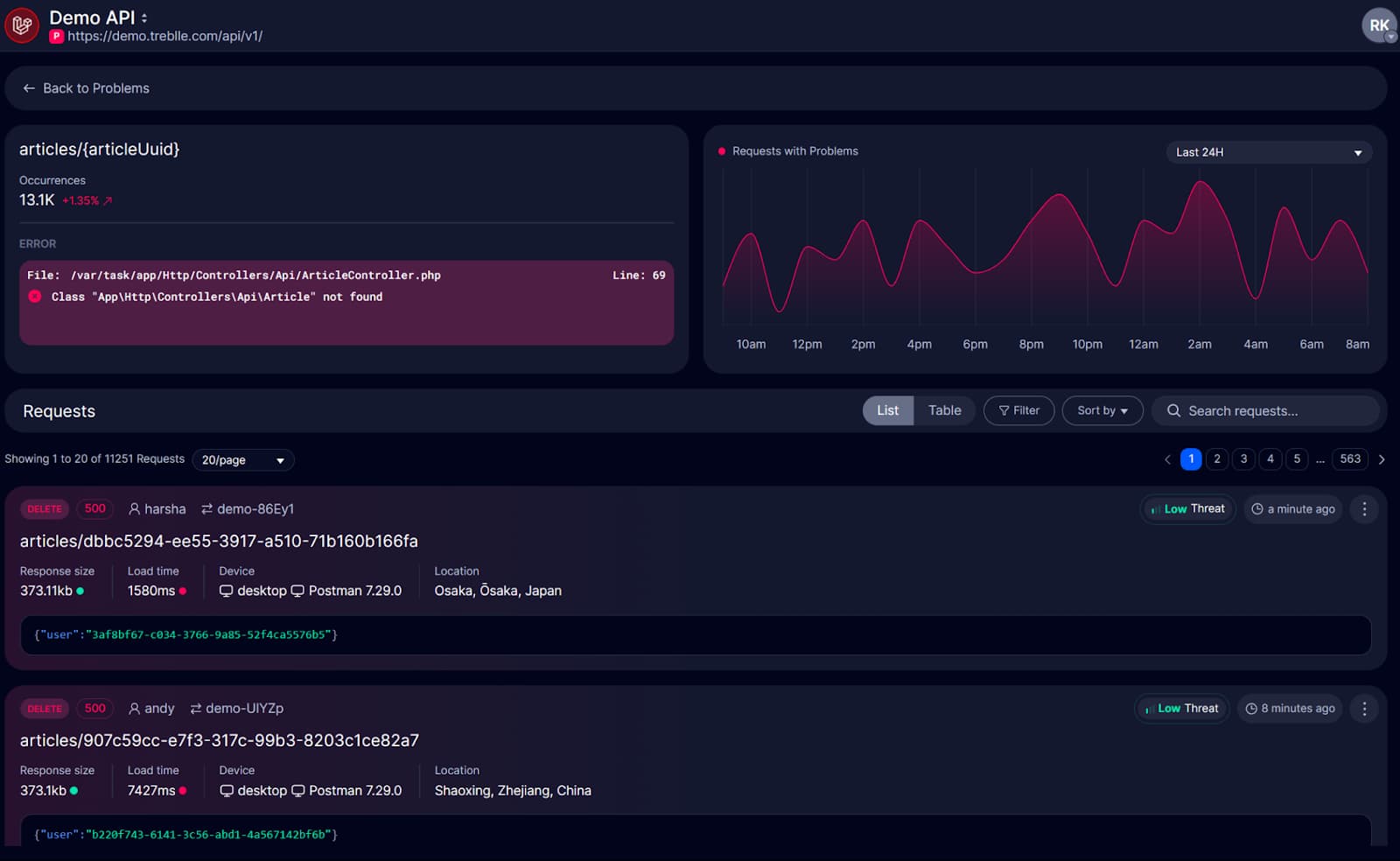
Treblle's tracing functionality lets you follow requests across your entire workflow, making it easy to pinpoint exactly where schema violations or anomalies occur in your LLM processing pipeline.
For example, you might notice that your /analyze-sentiment endpoint has a 15% contract violation rate, while your /extract-entities endpoint only has a 2% rate. This data tells you where to focus your prompt engineering efforts and which endpoints need stricter validation.
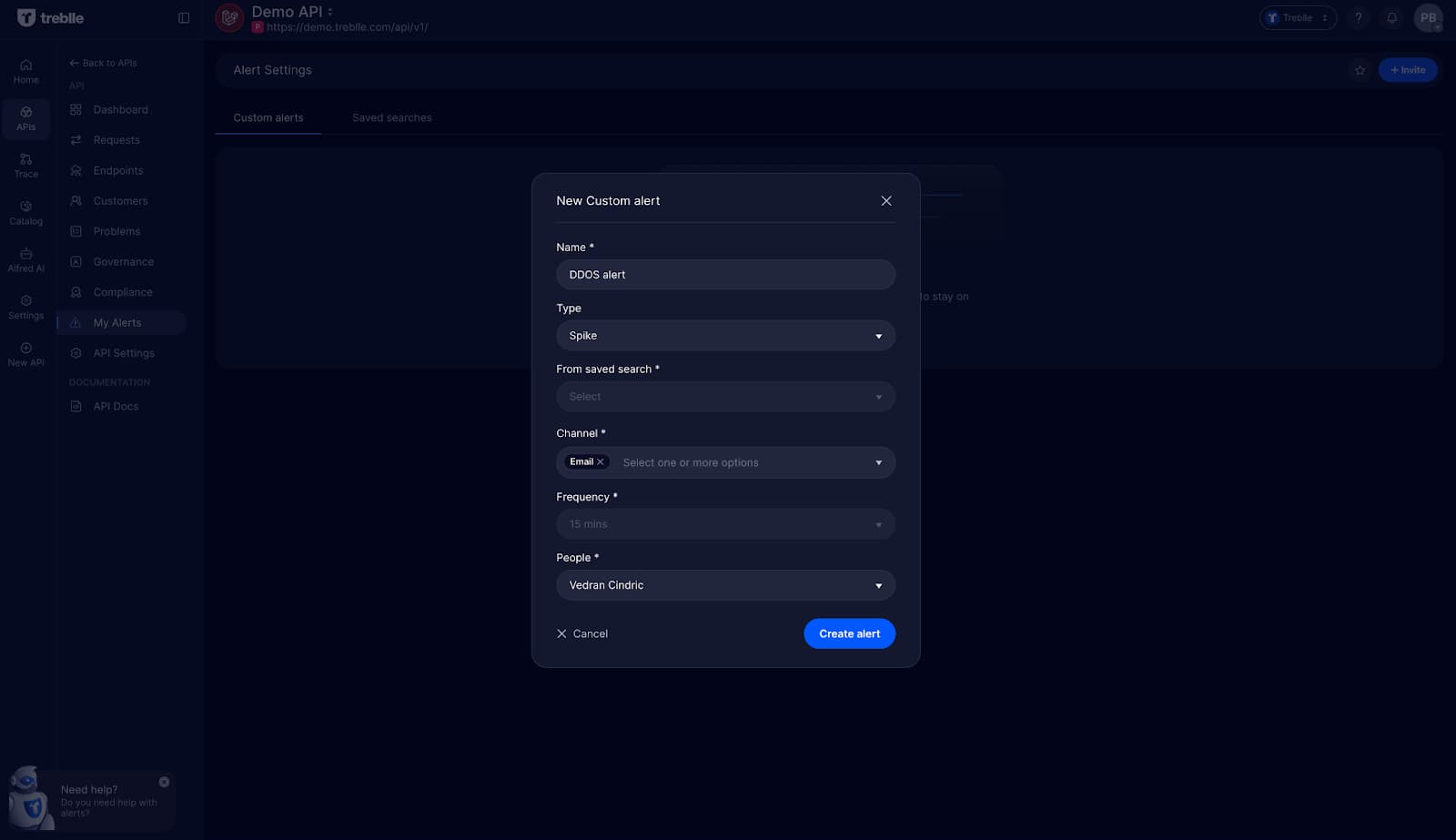
You can set up custom alerts for unexpected endpoint usage, schema mismatches, or compliance breaches. The custom alerts help you get notified immediately when your LLM starts behaving differently, allowing you to correlate changes in behavior with deployments, prompt updates, or model version changes.
Treblle's governance tools, API Insights, help you identify shadow or zombie endpoints and track compliance drift over time.
This historical view enables you to understand the long-term reliability of your AI-powered APIs and make informed decisions about when to implement additional safeguards.
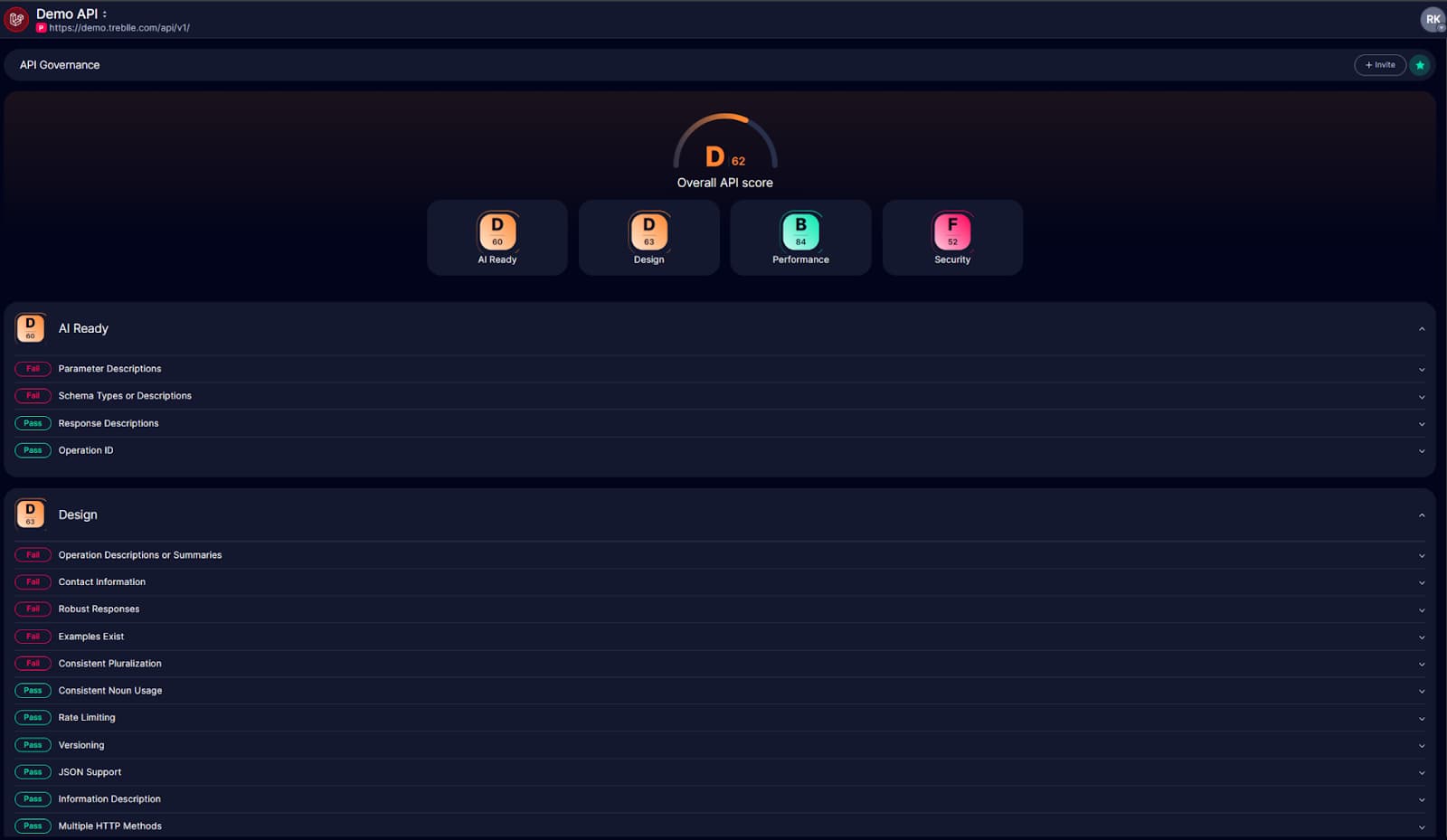
The governance report is critical for stability. When an LLM changes its behavior, you don’t want to rely on bug reports or support tickets to catch it. You want a dashboard that shows the degradation before it hits production.
If your LLM is triggering a support ticket, publishing content, or calling another API, you can’t afford quiet failures.
Contracts give you the structural rules.
Treblle enforces them, logs everything that violates them, and gives your team the context needed to fix or fine-tune fast.
This is especially important if:
You’re building external-facing AI APIs.
You’re chaining APIs in agent-based workflows.
You’re using retrieval-augmented generation (RAG), where response shape is critical.
You’re pushing automated actions based on LLM output.
In all of these cases, bad outputs don’t just “look off.” They cause bugs, user-facing issues, or data corruption.
And if you’re evaluating which AI APIs to build on, make sure they offer enough flexibility, documentation, and structure to handle LLM variability. Here’s a curated list of the best AI APIs currently powering serious production use cases.
You already know LLMs can drift. You’ve seen how minor output differences can break integrations. What looks like a simple JSON mismatch can hide in your logs for weeks.
The solution isn’t writing more tests. It’s building reliable interfaces and enforcing them where it counts.
Use contracts to define what’s allowed. Use Treblle to enforce those contracts, catch every violation, and monitor behavior as it evolves.
That’s how you build LLM workflows that don’t silently break. And that’s how you keep trust in systems built on probabilistic output.
Need real-time insight into how your APIs are used and performing?
Treblle helps you monitor, debug, and optimize every API request.
Explore TreblleAll Systems Operational
Gartner: Magic Quadrant, 2025
Gartner AI API Strategy, 2025
Everest Group: Enterprise App Integration Platforms, 2026


