
api-governance
How does Treblle scale on AWS without breaking the bank?

Summarize with




This one has been a long time coming. Like really long. It's been in the back of my head for months on end. But the day is finally here. I'm super happy to share the details of how do we actually scale Treblle without going bankrupt in the process.
Just like with many of my other blogs I like to start off by setting the tone with some music. I chose a scene from the movie Swordfish because it accurately depicts how I worked on scaling Treblle with all of the ups and downs. Besides that it really is a good mix of two different songs.
So then, like the song says, let's play to the music.
In case you missed my original blog post about the early days of developing Treblle you can find it here. In it I briefly mentioned that I dropped the entire project a few times because I couldn't get it to scale. Making sure we can scale at a cost without declaring bankruptcy in the first month was something I knew I had to solve before Treblle can exist. So I went ahead and set myself 3 core requirements for our infrastructure:
Did I set myself up for failure with such high requirements? - yes I did. Were there times I thought that hitting all 3 of those wouldn't be possible in my lifetime - yes sir. Did I give up - 3 times in 6 months. But, and there is a but. I never gave up completely. Whenever I failed I would leave it alone for a few weeks and then come back to it with a fresh pair of eyes. This is probably the most valuable thing I learned as a developer. When you're banging your head against a problem, step aside. Let it cool down. Don't work on that work on something else. Take a few hours, days or weeks off. Just do anything else. After your mind is ready you'll find a solution. It works. Every single time. Trust me - I know 😃
Here's how my path to scale looked like.
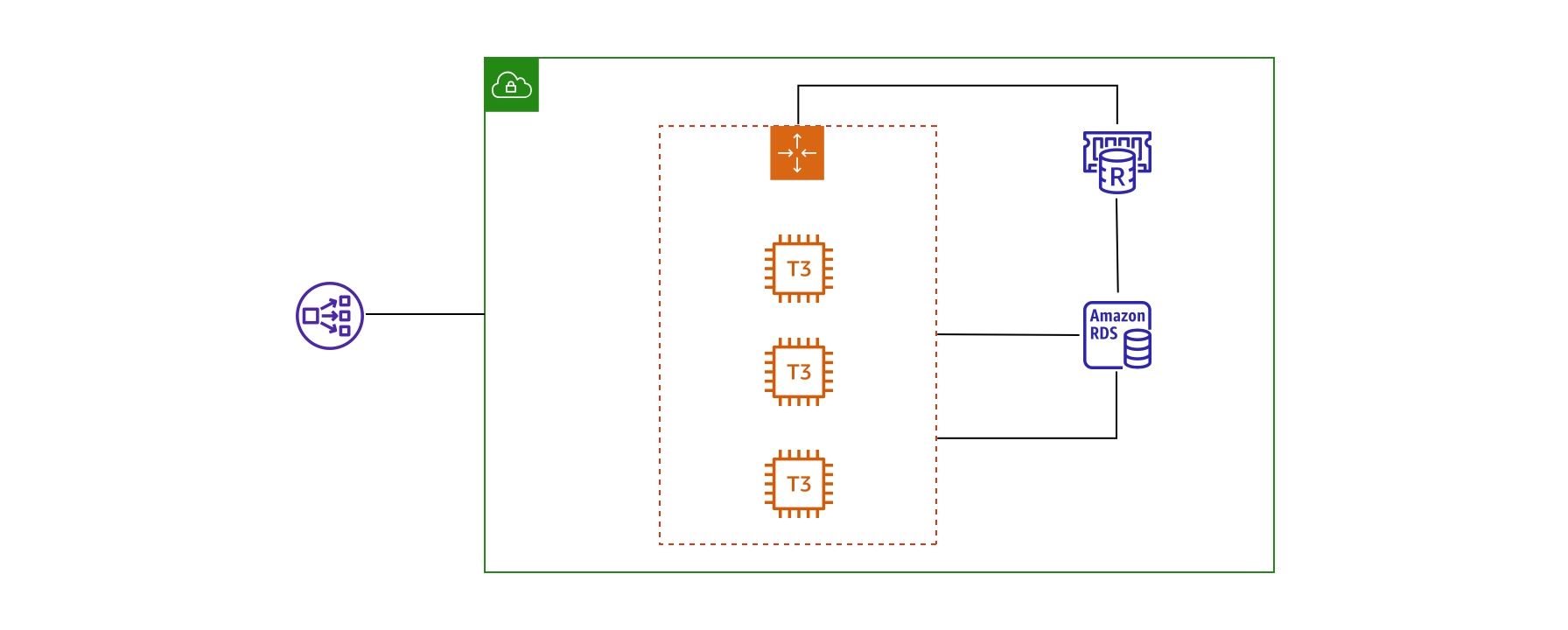
Before every serious infrastructure expert on Twitter starts to judge me, I have to note that, I'm by far no expert in AWS, infrastructure, DevOps and all that jazz...To use Johnny Ive's words, I'm just an unapologetically stubborn developer with a dream 😎 That's how I started approaching scaling.
Having seen many of my clients over pay for infrastructure to our beloved Jeff I wanted something better for myself and my project. A simple, elegant way of achieving the maximum with a minimum. Naturally the first thing I meaningfully started to explore was Load balancing and Auto scaling on AWS. It took me ages to grasp the concepts given I'm this old school guy used to SSHing into servers and messing with Ubuntu commands. I figured out that I could use a Load Balancer and attach that to an Auto Scaling group on AWS. It all sounds super complicated and fancy but what actually happens is this: all requests hit a load balancing server which serves like a traffic cop and directs traffic to one of many EC2 instances that run within your auto scaling group. So you generally start with two EC2 instances and then as you need more the auto scaling service by AWS can add more and more of these instances. It started looking like a potential solution so I explored more.
If you're in the AWS world you know at the end of your journey you just simply end up using ALL their services. The ones that you need and the ones that you didn't even know existed. That's what started happening here. As I started using load balancing in combination with auto scaling I needed to create Amazon Machine Images (AMIs) which essentially would have Ubuntu, Apache and PHP pre-installed so that every new EC2 instance has everything it needs. Then once I figured that out I needed a way to deploy the code to those instances. Then I started using Code Deploy and Github hooks. What happens there is when you push code on you Github repo Code Deploy would take that code and install it onto all EC2 instances that are in the autoscaling group. That was super tricky to set up, a lot of Ubuntu permissions, a lot of agony dealing with temporary files, local cache and Laravel peculiarities. But I somehow managed to get it up and running.
I spent days researching efficient auto scaling policies and testing them out. I used an RDS database, a serverless one which was super expensive but totally worth it. I also started using AWS ElastiCache for Redis which would allow me to connect all the instances to a shared Redis cluster. This approach can scale but there were so many problems and the entire process was quite cumbersome.
For instance the whole process was slow. I would deploy the code and it would take AGES for the code to show up on the EC2 instances. I was never even sure what code was actually running on a given instance. It got so bad I started using weird versioning policies to try to figure it out. Then half the time deployments would fail because of Ubuntu permissions, Laravel permissions, not being able to write to local cache, not being able to install composer packages and similar. Finally it still felt weird that I had to write these policies for launching EC2 instances that run Ubuntu, that need to be updated, patched, restarted and that can jam. I called it quits when I got into the logistics of running cron jobs and syncing them across X servers. It became this nightmare of a concept I felt could get out of control very quickly.
After working on this for a few months I concluded that this simply isn't what I'm looking for. Both in terms of process and money. Because, keep in mind, you have to pay for every EC2 instance you run and you never know how much you'll need. So you can't reserve instances in order to save money. In any case this would probably be OK for the first few months but it would probably collapse with time. It was a good try but not it didn't tick almost any of the rules I set for myself. Most importantly it didn't seem as elegant and simple. I've found that the best things in life, especially in development, are in its nature very simple.
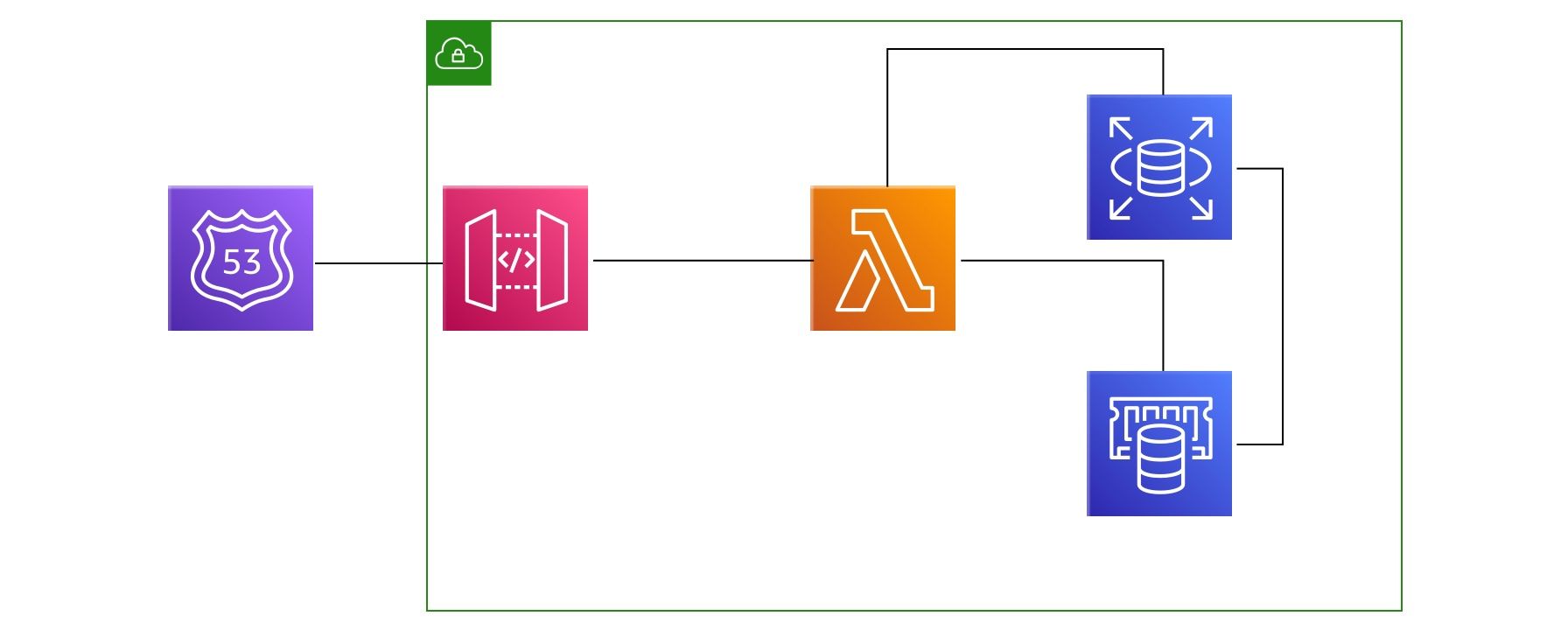
My second attempt didn't last long but it started by me learning more about AWS Lambda. It was the new hot trend. Serverless computing. You only pay for what you use. It's measured in milliseconds...It seemed great on paper but most people used it with Python or Node. Given I'm a PHP developer that turned out to be a no go.
During my research on how to make PHP run on Lambda I stumbled upon Bref at that time which was supposed to make that happen. I spent probably a month trying to get Laravel or any kind of a PHP application running on Lambda using Bref but I simply couldn't do it. There was always something: it was super slow and janky, cold starts were killing me, there were bugs and issues...It wasn't something I wanted to bet at that time.
This approach had promise but the tooling wasn't there yet, at least for PHP developers. When I looked at this it was early 2019. Laravel Vapor didn't exist and people were still exploring Lambda. I did however like the idea that you can literally run your entire app as a code for a certain amount of time. It's like this beautiful concept where you basically get punished for writing bad code that executes long. I always strived to write very efficient, optimized code that is above all fast.
So I decided to wait and see where AWS would take Lamda, when would some of the limitations be ironed out and finally when will the ecosystem catch up. It's very important that there is an ecosystem of developers around this because otherwise you can't learn how to use it, you can't read up on experiences of others and essentially you will be the one discovering all the early growing pains.
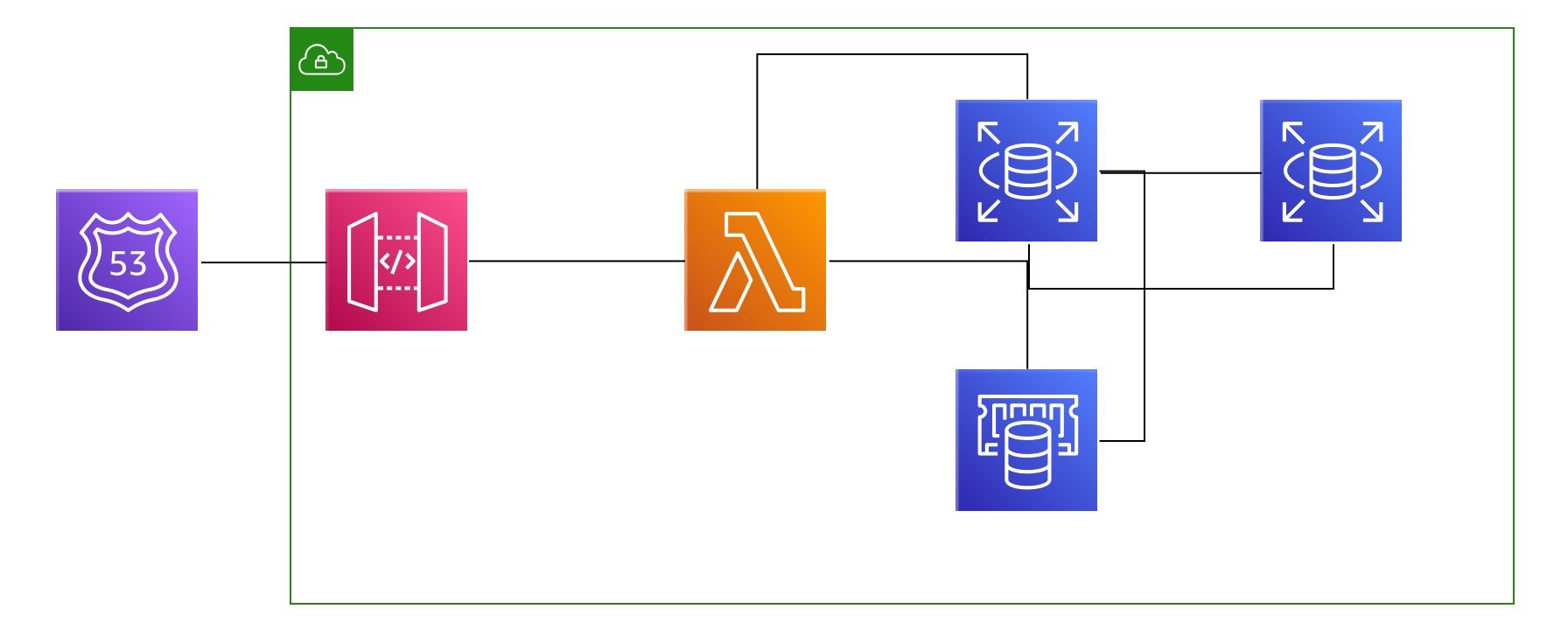
Fast forward a few months from my last attempt Laravel Vapor gets released. It was still early days but it allowed you, as a Laravel developer, to literally deploy the entire Laravel application to a Lambda function without any setup or hassle. You develop your app as you normally would and once you're ready you type in vapor deploy production and within a few minutes your application is ready and live. Vapor would essentially package the entire application, ZIP it, upload it to S3, deploy it inside of a Lambda function, upload images to a Cloudfront distribution, create all the services you need and connect them into one working thing of beauty. This enabled me, a regular software developer, to essentially build my own super scalable infrastructure without the need to open aws.amazon.com.
I loved it! I thought I finally cracked it and managed to solve my scaling issues. I started testing it out. It had a few problems but nothing I would deem as a blocker. It worked - magically. At the same time there were a lot of open questions about queues, performance, http support, cold starts and so one..The more I started getting into it the more I thought that this can't be my only solution.
My biggest fear was the database. Yes the entire infrastructure would be serverless, using various other services from AWS but at the end of day I would need to save the data somewhere. And trust me you can scale everything but scaling a MYSQL database is a whole different ball game. I simply knew, I alone, would never be able to do it and the cost of scaling a MYSQL database is HUGE. So Vapor can be a solution if I find a replacement for MYSQL or use something else.
Besides that I was also afraid to run everything off of the same code base. In case you didn't know, we have SDKs for various programming languages that send the log data from your API to our API. We take that log data, we have to read it, process it, do complicated computational stuff, analyze it and show it to you in near real time. With Laravel you can have a single application for both your web and API interfaces. Which is what we did, our entire stack was a majestic monolith that shared the same codebase - all the models, helper functions and business logic. So I was super afraid that if we messed something up on a completely unrelated part of the platform it could impact the intake process. Yes we could separate our code base into multiple different microservices running on Vapor and solve that problem. But in that case we have complications on scattered codebases and we still didn't solve the MYSQL problem.
So I gave up this path as well because I was afraid to use MYSQL as the only source of storing log data. But this time I knew that we would use Laravel and Laravel Vapor for everything else except the intake process. I also knew that the best scenario would be to not use MYSQL for the intake process at all. So again I took a break and started learning up on various different things that would help me solve this problem.
Now we get to the fun part. I desperately wanted to use Laravel in combination with Laravel Vapor to run our entire website as a Lambda function. There are no servers to install, maintain, no code base plus Vapor got even better but given our use case it simply wasn't enough. On the other hand I needed a solution that could be decoupled from our entire code base, isn't MYSQL based and can run for pennies on the dollar.
I started rampantly researching many different NoSQL databases, AWS solutions like DynamoDB, reading countless blog posts, spent weeks trying to figure things out but I simply couldn't find a solution that would fit my needs. At the same time I was developing multiple platforms for our agency clients and one of them processed more than 10TB of images per year without breaking a sweat. The reason why that was even possible was because we developed it, of course 😄, but beside that it was because it was using Amazon S3. The users would come to the website we built, they would select their local images and using the AWS PHP SDK and a little bit of Javascript they would upload the images DIRECTLY to AWS, in chunks if i might add. It was so beautiful and scalable that I started exploring if somehow we could use AWS S3 for our use case. I knew that you could upload directly to AWS S3 but you needed a signed request with a specific payload. So I started exploring how we can sign requests and maybe upload a log directly from the SDK by issuing some temporary permissions or credentials.
My path led to many roadblocks while trying to do this but, one night, randomly watching AWS videos on Youtube and exploring how Lambda functions worked I actually managed to figure it out.
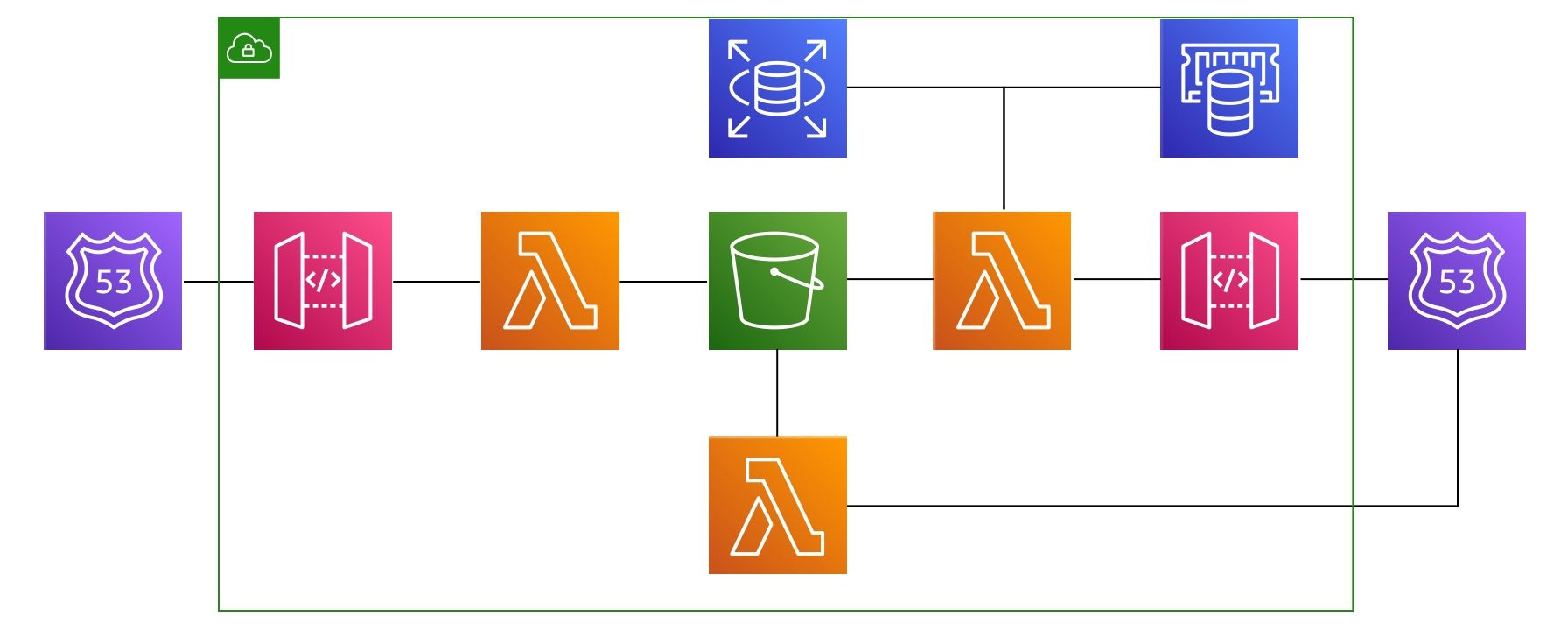
The premise of the idea was this: let's somehow send the data to a Lambda function directly from the SDK and then have the Lambda function store the file into AWS S3 as JSON.
So the first step in this process was to set up our domain on AWS Route 53. AWS wasn't our registrar so that took a few days but we finally got the domain under Jeff's control. Then I created a super simple AWS API Gateway v1 that connects to a Lambda function. It has only one endpoint with the POST method. It had to be Gateway v1 and not the 50% cheaper v2 because of one simple thing: usage plans. So I was actually able to connect our website with the API Gateway in terms of API keys and plans. So all the plans on our website also exist on the API gateway. When you make an account on our website in the background we essentially make a new API Gateway key as well and assign you to a plan. Why do we do this? Well because AWS takes care of all the API limits, making sure you don't go overboard, making sure all the validation is done on their side. So no MYSQL queries to our database, no calls to our server - nothing. Pure AWS - all the way 🎉

After I got the API Gateway to work very closely with our website I wanted to make sure that our SDKs were calling a more friendlier URI than what AWS gives you. So I connected a custom subdomain rocknrolla.treblle.com. Yes, it's a reference to a Guy Ritchie movie with the same name RocknRolla. Great movie, great cast - you should watch it! Anyhow, once the custom domain was connected it was time to make our Lambda function.
So the only purpose of the Lambda function would be to take the data it gets from our SDK, via the API Gateway, and dump it into Amazon S3, the most distributed and scalable system in the world. To do that I used NodeJS, and in 23 lines of code I wrote a simple function that does exactly what it needs. Stores the RAW request data, which is your regular JSON, as a .json file into an S3 bucket.
VOILA! Now I had a completely scalable intake solution that didn't require a database because all the data was stored on S3. Infinitely scalable, distributed, cheap as f***, fast and more importantly totally maintained by AWS.
That isn't exactly the end of the journey for our logs but it sure took care of the most complicated part. After the log is stored into the S3 bucket I have another Lambda function which simply notifies our processing pipeline, developed in Laravel powered by Laravel Vapor. That processing pipeline loads the file from the S3 bucket and starts as a 5 step process of reading, transforming, enriching the data and then storing parts of that data into a database. This process is entirely based on Laravel Queued jobs and running inside another infinitely scalable and dirt chip service AWS has called SQS.
Laravel Queues combined with AWS SQS allow us to background long lasting processes and not have to execute them straight away. It's basically like saying: "hey processing pipeline we have a new job in the queue when it's next in line and you have time please process it." Using that approach each log creates up to 5 different background jobs that are executed in sequence. But in order to have the real time feeling for you as a user we show you the log, in your Treblle dashboard, as soon as the the first job is finished processing. That part is a simple illusion that I think even David Copperfield would be proud of. In the first job we literally do only what we need to show you the request on the dashboard. By the time you see the request we are already on job two. By the time you hover towards the request we are on job 3. By the time you click on it we are on job 4.

To process a request and one of it's jobs we need about 500ms. So from your SDK to your Treblle dashboard in more or less 500ms. Given the amount of information we give you this is amazing. Just to give you a glimpse of what we have to understand or get: the location of the request, parse out the device information, server information. Map the request to an endpoint, check if the URL has dynamic parts in it, compile docs based on the request, compare the docs to multiple other previous versions...and finally store a lot of the data in MYSQL and show it you in a way that anyone on the team can read it. Of course we do a lot more but in broad strokes you now know what kind of trouble we go through to show you a single request. Also we don't stop and we are improving our processing pipeline every week, trying to push performance to the next level!
As you can see this approach ticks all the requirements I set at the beginning of my scaling journey. Because we are using AWS API Gateway we are piggybacking on top of AWSes global infrastructure that helps reduce latency and brings our endpoint closer to you "free of charge". Next, we are using a Lambda function with just 23 lines of code that stores the RAW data into AWS S3. This allows us to reach almost infinite scalability without running any servers, any databases nor have to maintain anything. Finally our entire post processing is built using Laravel and Laravel Vapor which again runs everything without any servers in a Lambda function. To top it all of the entire process is spun off into multiple background jobs that get executed in sequence inside AWS SQS.
For you as the user of Treblle this means our intake API never goes down, it has next to no impact on your API and we can handle as many requests as you can without breaking a sweat. But optimization for us starts on our SDK level. We develop them with your API in mind. So we use a fire and forget approach when making asynchronous requests isn't possible. If the language supports it we even use queued and background jobs to push logs to us. All in an effort to literally reduce any impact on your API and make sure it's running 24/7. Even if our processing pipeline and/or our website are completely broken down, not working, kaput we will STILL be receiving logs from your API requests and as soon as we are back up we will process those logs and you'll see them. The second part hasn't yet happened, and we'll make sure it doesn't but just in case you were wondering.
Now you're probably wondering about the cost of this near to infinite scale on AWS. I recently tweeted this screenshot from our Laravel Vapor dashboard. On it you can see that we processed over 7M queued jobs and handled over 1.3 million HTTP requests in the past 30 days. On top of that you can see that the average queue duration is 500ms 🤯 You can also see that we ONLY paid 65 USD to handle all of that and around 100 USD more for the RDS database and AWS S3 fees. So we're able to run our entire stack for less than 200 USD per month at this scale.
We've been running on this architecture for the past 6 months without any down time and we keep doubling the amount of API requests we process every month. I haven't spent one single night thinking about our infrastructure. It simply just works. It works because I've spent half a year trying to isolate myself, our code base, and our future employees from the entire process. At its essence it's such a simple and pure idea of running completely on the AWS infrastructure, controlled by a countless army of DevOps pros that Jeff pays.
So I'd like to ask for a round of applause 👏 for all the DevOps teams working at AWS that have actually made Treblle possible. Making sure the Lambda functions scale, making sure S3 scales, making sure API Gateway scales...
Many of you have asked me how we scale, how am I not worried, how we can process as much data. Now you know. It's a symphony of multiple serverless processes that are as scalable as Amazon is. Will we stop there - no we won't : ) There is more room to improve and I'll share some more insights on what we are doing on top of all of this.
I hope you enjoyed the read, I hope it can help you scale something you are working on but above all I hope it puts a little bit of more trust into Treblle as a product.
As always you can follow me on Twitter, add me on LinkedIn or read more blog posts on our blog.

Oh yeah, almost forgot - I just recently published a FREE E-book on how to build amazing, sclable APIs. If you're interested get it right here => https://treblle.com/ebooks/the-10-rest-commandments.
All Systems Operational
Gartner: Magic Quadrant, 2025
Gartner AI API Strategy, 2025
Everest Group: Enterprise App Integration Platforms, 2026


