
api-design
Understanding API Caching Architecture for Enterprise Systems

Summarize with





API caching architecture plays a crucial role in enterprise systems, helping to enhance performance and reduce server load. By storing frequently requested data closer to users, APIs can serve responses much faster. This not only improves the end-user experience but also minimizes the strain on backend servers.
Implementing effective caching strategies can significantly cut costs associated with computation, database operations, and data transfer. For instance, smart caching can lead to a reduction in backend load and network usage, making it a savvy choice for businesses looking to optimize resources.
Moreover, companies like The Weather Company have adopted specific caching settings, allowing them to reuse API responses efficiently, which is particularly beneficial during high-traffic events like storms.
By understanding and leveraging API caching architecture, enterprise teams can boost their API's reliability and performance while keeping operational costs in check. It's all about maximizing your resources to ensure your systems run smoothly and effectively.
In this article, we will discuss everything about API caching and how tools like Treblle can help you validate your API caching process.
Caching strategies can be a game-changer for your API performance. The core idea is to store previously computed or fetched responses, allowing subsequent requests to be served from a faster layer. This reduces latency and elevates user experience while lightening the load on your backend systems.
When applying caching strategies, consider the context. For frequently accessed data, in-memory caching can be incredibly effective. On the other hand, for static content or data that doesn’t change often, edge caching can save bandwidth and improve load times.
The Cache-Aside pattern offers a flexible approach to managing API responses while keeping control over data freshness. In this strategy, the application code is responsible for interacting with the cache and the data store.
When a request comes in, the application first checks the cache for the requested data. If it’s there, great! If not, the application retrieves it from the database, stores it in the cache for future requests, and serves the user.
This pattern not only speeds up response times but also enables precise control over how and when data is refreshed. You can implement strategies like stale-while-revalidate, such as where users receive cached data while a background process fetches updated information. This way, users enjoy quick responses, even when the data is refreshing, ensuring a smooth overall experience.
Read-Through and Write-Through caching are powerful strategies that can significantly enhance your API's performance. With Read-Through caching, when an application requests data, it first checks the cache.
If the data is not available, it retrieves it from the database, stores it in the cache, and then returns the response. This method not only speeds up access for subsequent requests but also ensures that the cache is populated with fresh data.
On the other hand, Write-Through caching takes this a step further by updating the cache simultaneously with the database. When a new entry is added or an existing one is modified, the change is written to both the cache and the database at once. This keeps the cache consistent with the database, ensuring users receive the most up-to-date information without dealing with stale data.
By implementing these strategies, teams can strike a balance between performance and data accuracy, enhancing user experience while minimizing backend load.
Write-back caching is a fantastic approach for optimizing high-performance scenarios in your API. By allowing changes to be written to the cache first, you can significantly enhance response times, as users don’t have to wait for database updates. This means they get quick feedback, while the actual database gets updated in the background.
This strategy is particularly useful when you can tolerate some temporary inconsistency in your data. For instance, in applications where real-time accuracy isn’t critical, the write-back cache can handle bursts of activity without bogging down your database. The cache acts as a buffer, absorbing write requests and ensuring that your backend remains responsive even under heavy loads.
Implementing write-back caching can lead to improved throughput and reduced latency, making it an essential tool for teams looking to enhance API performance without sacrificing user experience.
Choosing the right caching strategy can feel like navigating a maze, but it doesn't have to be overwhelming. Start by assessing your API's specific needs, such as data access patterns and user expectations. Each API Caching strategy, be it Read-Through, Write-Through, or Cache-Aside, has its strengths and ideal use cases.
Consider the trade-offs between performance and data freshness. For instance, if your API handles high-frequency data requests, a strategy that prioritizes speed, such as Write-Through caching, might be ideal. Conversely, if your application demands real-time accuracy, you might lean towards Read-Through caching. By understanding the context and requirements, you can select a strategy that not only optimizes performance but also enhances user experience.
Always keep in mind that monitoring and adjusting your caching strategy is essential. As your API grows and user behavior evolves, the effectiveness of your chosen method may change. Regularly revisiting your strategy ensures that you're making the most of your caching capabilities, keeping your API responsive and efficient.
HTTP caching for APIs is a powerful way to boost performance and minimize latency. It works by storing responses from the server, allowing subsequent requests for the same resource to be served from the cache rather than fetching them again from the backend. This dramatically speeds up response times and reduces the load on servers, which is especially beneficial during peak traffic times.
Understanding the mechanics of HTTP caching involves two key concepts: freshness and staleness. Freshness refers to the data's currentness; staleness indicates how outdated the cached information may be. To manage this balance, HTTP headers play a crucial role. Headers like Cache-Control and Expires help define how long a response should be cached. A well-defined Time to Live (TTL) ensures that data is refreshed periodically, allowing users to access timely information without overwhelming your backend systems with constant requests.
Validation strategies also come into play. For example, you might use ETags or Last-Modified headers to check if the cached data is still valid or needs an update. By combining these mechanisms, APIs can efficiently manage their cached data while ensuring that users receive up-to-date responses, thus striking a balance between speed and accuracy. This thoughtful approach to caching not only improves performance but also enhances the overall user experience.
HTTP caching directives like Cache-Control, max-age, s-maxage, and Expires play a crucial role in managing how data is cached and served. Cache-Control allows you to specify the caching behavior, such as whether responses can be cached public, or are specific to a user private). The max-age directive tells caches how long they can consider the response fresh, while s-maxage is specifically for shared caches, overriding max-age for these scenarios. The Expires header is a legacy way to set an expiration date for cached content.
When it comes to cache types, private caches store data for a single user, ensuring personalized responses. In contrast, shared caches hold data accessible to multiple users, which can enhance performance but may introduce concerns about data freshness.
An example of a canonical header is Link: <https://api.example.com/resource>; rel="canonical", which helps indicate the preferred version of a resource, guiding caches on how to handle duplicates effectively.
Conditional requests using ETags and Last-Modified headers help ensure that cached responses remain fresh while saving bandwidth. When a client requests a resource, it can include an If-None-Match header with the ETag value from a previous response.
If the resource hasn’t changed, the server responds with a 304 Not Modified status, indicating that the cached version is still valid and saving the cost of sending the complete response again.
Similarly, the If-Modified-Since header allows clients to specify a date. If the resource hasn't been modified since then, the server returns a 304 status, again avoiding unnecessary data transfer. For example, a request might look like this:
GET /api/resource HTTP/1.1
If-None-Match: "123456"
If-Modified-Since: Tue, 01 Jan 2023 12:00:00 GMT
In response, if the data hasn’t changed, the server would simply reply with:
HTTP/1.1 304 Not Modified
This clever use of conditional requests not only enhances performance but also optimizes bandwidth usage, making it a win-win for both the server and the client.
When it comes to caching, understanding how variants and cache keys work is essential. Caches build their keys based on the URL, HTTP method, and selected headers, like Accept-Language. Using the Vary header can help ensure that different user preferences are respected, but be cautious with User-Agent, as it can lead to cache fragmentation and inefficiencies.
Emerging strategies like No-Vary-Search are making waves by normalizing query parameters. This approach focuses on ignoring less relevant query params to improve cache hit rates, making your API responses even quicker and more efficient. It’s an exciting development in the caching landscape that can streamline performance and enhance user experience!
Using stale-while-revalidate and stale-if-error directives can significantly enhance user experience during API interactions. These two caching strategies allow users to receive immediate responses from cached data while the system updates the cache in the background or handles errors gracefully.
By employing stale-while-revalidate, users get the cached version while fresh data is fetched, ensuring they aren’t left waiting. stale-if-error steps in during downtime, serving stale data instead of returning an error. This is especially useful for maintaining seamless user experiences, as it keeps your API functional even when issues arise.
These directives are part of the standard HTTP caching extensions, making them accessible for implementation without reinventing the wheel. By integrating them, you not only improve performance but also enhance the reliability of your API, keeping users satisfied and engaged.
Designing a caching strategy for your API involves a thoughtful approach that balances performance, data freshness, and user experience. Here’s how to design your API caching strategy
Understanding the "edge + gateway + app" cache hierarchy is key to optimizing API performance. Each layer has a distinct role: the edge layer minimizes latency by caching responses close to users, the gateway layer handles routing and additional caching to balance loads, and the app layer provides fine-grained control over data freshness and validation.
By strategically caching at each level, you ensure faster access to frequently requested data while maintaining accuracy. This approach not only enhances user experience but also reduces backend strain, allowing your API to operate smoothly even during high-traffic periods. Implementing this hierarchy creates a robust caching ecosystem that effectively meets user demands.
When developing a TTL strategy matrix, it’s essential to customize Time to Live settings based on the type of data you're handling. For static or reference data that rarely changes, longer TTLs make sense, ensuring that users benefit from quick access without unnecessary refreshes. Meanwhile, for hot or rapidly changing data, opt for shorter TTLs to keep the information timely and relevant.
Combining TTLs with validators can further enhance this strategy. By implementing validation techniques, like ETags or Last-Modified headers, you can ensure that even when cached data is served, it remains accurate. This thoughtful approach not only optimizes performance but also guarantees that users consistently receive the most up-to-date information, enhancing their overall experience.
When it comes to managing query parameters in API caching, having stable ordering is vital. This ensures your caches generate consistent keys, which is crucial for effective retrieval. Using the Vary header judiciously, like with Accept-Language, can help tailor responses based on user preferences, but be cautious; overusing headers like User-Agent can lead to cache fragmentation and inefficiencies.
Excitingly, the experimental No-Vary-Search strategy is emerging, focusing on normalizing query parameters to enhance cache hit rates. By ignoring less relevant parameters, this approach streamlines caching and improves performance. It's a promising development that could simplify the caching landscape while boosting user experience.
Cache invalidation is crucial for maintaining the accuracy and performance of your API. Strategies like TTL (Time to Live) expiry ensure that cached data is refreshed after a specified duration, preventing users from accessing stale information. Event-driven purges, such as webhooks or Change Data Capture (CDC), can trigger immediate cache updates whenever the underlying data changes, keeping cached responses in sync.
Additionally, using CDN surrogate-key purges allows for efficient invalidation of groups of cached objects, making it easier to manage related resources collectively. This ensures that when one piece of data changes, all associated cached responses can be updated, enhancing both speed and reliability. These methods work together to create a robust caching strategy that keeps your API performing at its best.
When it comes to handling influxes of requests, implementing stampede protection is essential. Techniques like request collapsing at CDNs or reverse proxies can help prevent overwhelming your backend by aggregating similar requests, ensuring that only one request is processed at a time. This not only improves efficiency but also minimizes server strain during peak usage.
Additionally, utilizing app-level mutexes and jitter can further enhance performance. A mutex allows you to control access to resources, preventing simultaneous calls that could lead to resource exhaustion. Adding jitter introduces randomness in request timing, which helps in spreading out the load and reducing the chance of bottlenecks.
Finally, leveraging the stale-while-revalidate directive allows you to serve stale data safely while fresh data is fetched, keeping users happy and engaged even during high traffic periods.
Monitoring cache performance is vital for ensuring your API operates smoothly and efficiently. By monitoring cache hit rates, you can gauge the effectiveness of your caching strategies. A high cache hit rate indicates that data is being served quickly from the cache, reducing the load on your backend and enhancing user experience.
However, it's not just about speed. You also need to monitor data freshness. Stale cached data can mislead users, so implementing validation techniques, like setting Time to Live (TTL) or using ETags, ensures that your API serves accurate information.
This balanced approach to monitoring cache performance allows your API to thrive while keeping user satisfaction at the forefront.
Critical Cache Metrics and KPIs
Understanding critical cache metrics and KPIs is essential for optimizing API performance. Key metrics, such as cache hit rate, which measures the percentage of requests served from the cache, help evaluate how effectively your caching strategies are working. A high cache hit rate typically translates to faster response times and reduced server load.
Another important KPI is cache eviction rate, indicating how often items are removed from the cache. This metric can signal issues such as insufficient cache size or suboptimal TTL settings.
By closely monitoring these metrics, you can make informed decisions to enhance your caching strategy, ensuring users receive timely and accurate data while keeping your backend systems running smoothly.
Monitoring these metrics consistently allows you to adapt to changing user behavior and optimize your API's performance over time. Adjustments based on this data can lead to a more efficient and responsive API, ultimately improving user satisfaction and engagement.
Treblle's API Intelligence Platform is designed to supercharge your cache observability, offering real-time insights that help you understand how cached data is performing. With detailed analytics for every API request, you can easily identify cache hit rates and eviction patterns, ensuring that your caching strategies are practical and efficient.
Integrating Treblle into your workflow not only enhances performance but also empowers your team with the data needed to make informed decisions about your caching strategies.
Need real-time insight into how your APIs are used and performing?
Treblle helps you monitor, debug, and optimize every API request.
Explore Treblle
Caching can significantly enhance API performance, but it also introduces unique security challenges, especially for cached endpoints. One best practice is to ensure that sensitive data is not stored in the cache, as this could lead to unauthorized access if cached responses are served inadvertently.
Another critical measure is to implement proper cache control headers, specifying which resources can be cached and for how long. By using headers like Cache-Control: no-store, you can prevent sensitive information from being cached at all. Additionally, employing techniques such as token-based authentication ensures that only authorized users can access certain API endpoints, even if the responses are cached.
Regularly auditing and monitoring cached data is also essential. This not only helps identify potential security vulnerabilities but also ensures compliance with data protection regulations. By following these practices, you can enhance the security of your cached API endpoints while enjoying the performance benefits of caching.
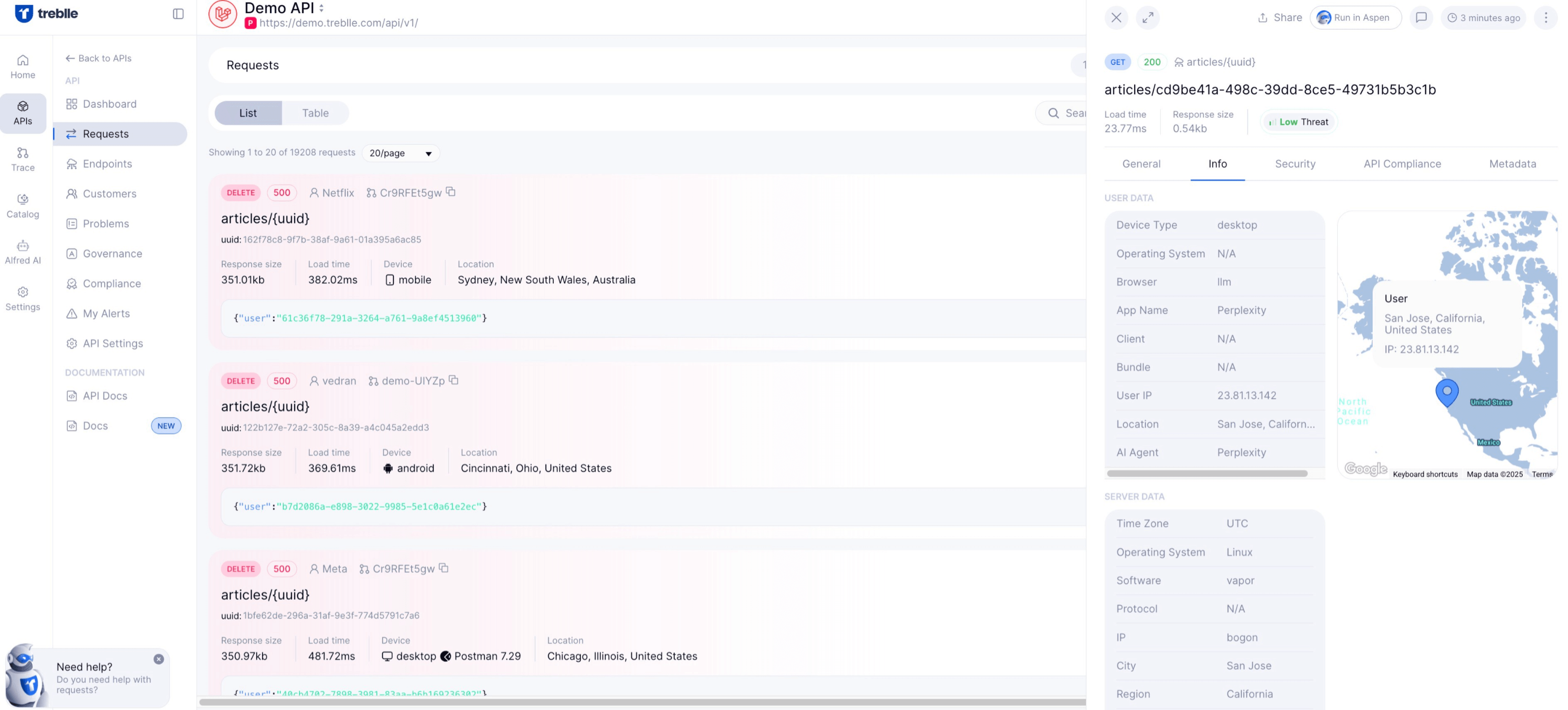
API governance and compliance are essential for maintaining the integrity and security of your cached data. When caching API responses, ensure that sensitive information is handled with care, avoiding the storage of any personal or confidential data in the cache. This practice helps prevent unauthorized access and protects user privacy.
Additionally, implementing strict cache control policies is crucial. Use headers like Cache-Control to specify which data can be cached and how long it can be stored. Regular audits of cached data help identify potential vulnerabilities and ensure compliance with data protection regulations. By prioritizing governance and compliance, you can leverage the benefits of caching while safeguarding your API's integrity.
Treblle automatically checks Governance and Compliance on each API request and gives you a real-time score along with a detailed breakdown on what best practices are not being followed:
Rolling out API caching is a crucial step to enhance performance and reduce backend load. Start by assessing your API’s data access patterns and identify which responses are frequently requested. This will help you determine what to cache and the appropriate caching strategy to implement.
Next, establish your caching layers. Consider using a combination of edge caching for static content and in-memory caching for dynamic data. Ensure you set appropriate Time to Live (TTL) values for your cached data to balance freshness and performance. Monitoring cache hit rates is essential, as it informs you about the effectiveness of your caching strategy over time.
Finally, implement validation mechanisms like ETags or Last-Modified headers to ensure users receive accurate, up-to-date information. Regularly revisit and adjust your caching approach as user needs evolve, ensuring your API remains responsive and efficient.
When implementing inventory endpoints, marking cacheability and sensitivity is crucial. You'll want to define which data can be cached and for how long, ensuring you don't inadvertently serve outdated or sensitive information.
For example, public inventory data can be cached to improve performance, while sensitive user-specific data should be marked as non-cacheable to protect privacy.
Utilizing headers like Cache-Control can help you manage this effectively. By setting directives such as public, private, or no-store, you can control how and when data gets cached. This careful approach ensures that users receive timely updates without compromising data security, creating a seamless experience while maintaining integrity.
Deciding on cache hierarchy and TTLs is essential for optimizing API performance. A well-structured cache hierarchy, such as "edge + gateway + app," enables faster data serving and reduces backend load. Each layer plays a specific role: edge caching minimizes latency for users, while the gateway manages traffic and performs additional caching.
Setting appropriate Time to Live (TTL) values is crucial for balancing data freshness and performance. Longer TTLs work well for static content, ensuring quick access, while shorter TTLs are better for frequently changing data, helping you maintain accuracy. This thoughtful approach keeps your API responsive and enhances user experience while managing resources effectively.
Adding validators like ETags and Last-Modified headers to your API responses is a smart way to ensure that cached data remains fresh while saving bandwidth. These validators help your API determine whether the cached version is still valid or if it needs to be updated.
When a client makes a request and includes an ETag in the If-None-Match header, the server can quickly check for changes and respond with a 304 Not Modified status if the data hasn't changed. This means no unnecessary data is sent, keeping things efficient.
Likewise, the If-Modified-Since header allows clients to specify a timestamp. If the resource hasn’t been modified since that time, the server responds with a 304 status, making for a leaner exchange.
By implementing these strategies, you create a system that not only boosts performance but also optimizes bandwidth usage, ensuring that your users always get the most accurate and timely information without overloading your server.
When it comes to managing cache purging, wire purge paths like surrogate keys and webhooks play a vital role in keeping your API responses accurate and timely. Surrogate keys allow you to group related cached objects, making it easier to invalidate a set of entries when one piece of data changes. This method is particularly effective when dealing with grouped resources, ensuring that your cache remains coherent and relevant.
Webhooks provide a proactive approach to cache invalidation. By setting up webhooks that trigger cache purges upon specific events, like data updates or changes, you can automatically keep your cached data fresh without manual intervention. This not only streamlines your operations but also enhances user experience, as users receive accurate data in real-time. Together, these strategies create a robust framework for maintaining cache integrity across your API.
Implementing stampede protection is vital for managing high request volumes effectively. Techniques like request collapsing at CDNs or reverse proxies can aggregate similar requests, ensuring only one request hits the backend at a time. This significantly enhances efficiency and reduces the risk of overwhelming your servers during peak periods.
In addition to CDN strategies, employing app-level mutexes can prevent simultaneous calls to the same resource, which might lead to resource exhaustion. Adding jitter to request timing creates randomness that spreads out traffic, further alleviating bottlenecks. Finally, utilizing the stale-while-revalidate directive allows you to serve stale data while fresh information is being fetched, keeping users satisfied even when the backend is busy.
These combined strategies create a robust framework that helps maintain performance and reliability, allowing your API to handle traffic surges gracefully.
Instrumenting metrics and alerts for your API is crucial for optimal performance monitoring. Key metrics like Cache Hit Rate (CHR), Time to First Byte (TTFB), and origin egress provide valuable insights into how well your caching strategies are working. CHR helps assess the effectiveness of your caching layer, while TTFB measures the speed at which your server responds to requests, indicating potential latency issues.
Monitoring origin egress is essential as it tracks the amount of data sent from your origin server. This helps identify unnecessary data transfer, allowing you to optimize your caching strategy further. Setting up alerts based on these metrics ensures that your team is promptly informed of any anomalies, enabling quick corrective actions to maintain API performance and user satisfaction.
Running A/B tests or canary deployments is a smart way to evaluate the impact of your caching strategies. By comparing performance metrics such as latency, egress costs, and infrastructure expenses, you can determine the most effective approach for your API. This method not only provides concrete data but also helps in fine-tuning your caching setup for optimal efficiency.
Iterating based on these findings is essential. If one caching approach reduces latency significantly but increases egress costs, you might want to strike a balance that meets your performance goals without breaking the bank. Keeping a close eye on these metrics enables data-driven decisions that enhance both user experience and resource management.
When it comes to safely operating caching, Treblle has your back! Our platform provides real-time analytics and actionable insights for every API request, allowing you to monitor how cached data performs and ensuring that you serve the freshest content possible.
With automated security and governance features, you can set cache control policies that keep sensitive information out of the cache. This means you can enjoy the performance gains of caching while maintaining compliance and protecting user data. By integrating Treblle into your workflow, you can focus on building great features while we handle the intricacies of cache management, ensuring your API remains responsive and reliable.
Regular monitoring and quick adjustments based on analytical insights allow your caching strategies to evolve with changing user needs, all while keeping your API optimized and efficient.
Custom alerts play an essential role in keeping your API performance in check. By setting up notifications for sudden latency spikes, error bursts, or unusual traffic patterns, you can quickly respond to potential cache issues or stampede events.
For instance, if the system detects a sudden rise in response times, it may signal that your cache isn’t functioning optimally or that an unexpected load is hitting your backend.
Additionally, these alerts can help you identify when specific cache entries are being hit too frequently, indicating a potential stampede situation.
By monitoring these metrics, you can take proactive measures to adjust your caching strategies or implement protective mechanisms, ensuring a seamless user experience even during peak demand periods. This kind of vigilance is crucial for maintaining API reliability and performance.
Ensuring compliance checks to prevent the accidental caching or exposure of Personally Identifiable Information (PII) and Payment Card Industry (PCI) data is paramount for any API. Implementing strict cache control policies, such as using Cache-Control: no-store, helps to safeguard sensitive information from being cached. By marking data as non-cacheable, you can effectively reduce the risk of unauthorized access.
Additionally, regular audits of cached data help identify potential vulnerabilities. Monitoring your cache for sensitive responses ensures compliance with data protection regulations, like GDPR and PCI DSS. By integrating these practices, you can enjoy the performance benefits of caching while maintaining robust security for your users.
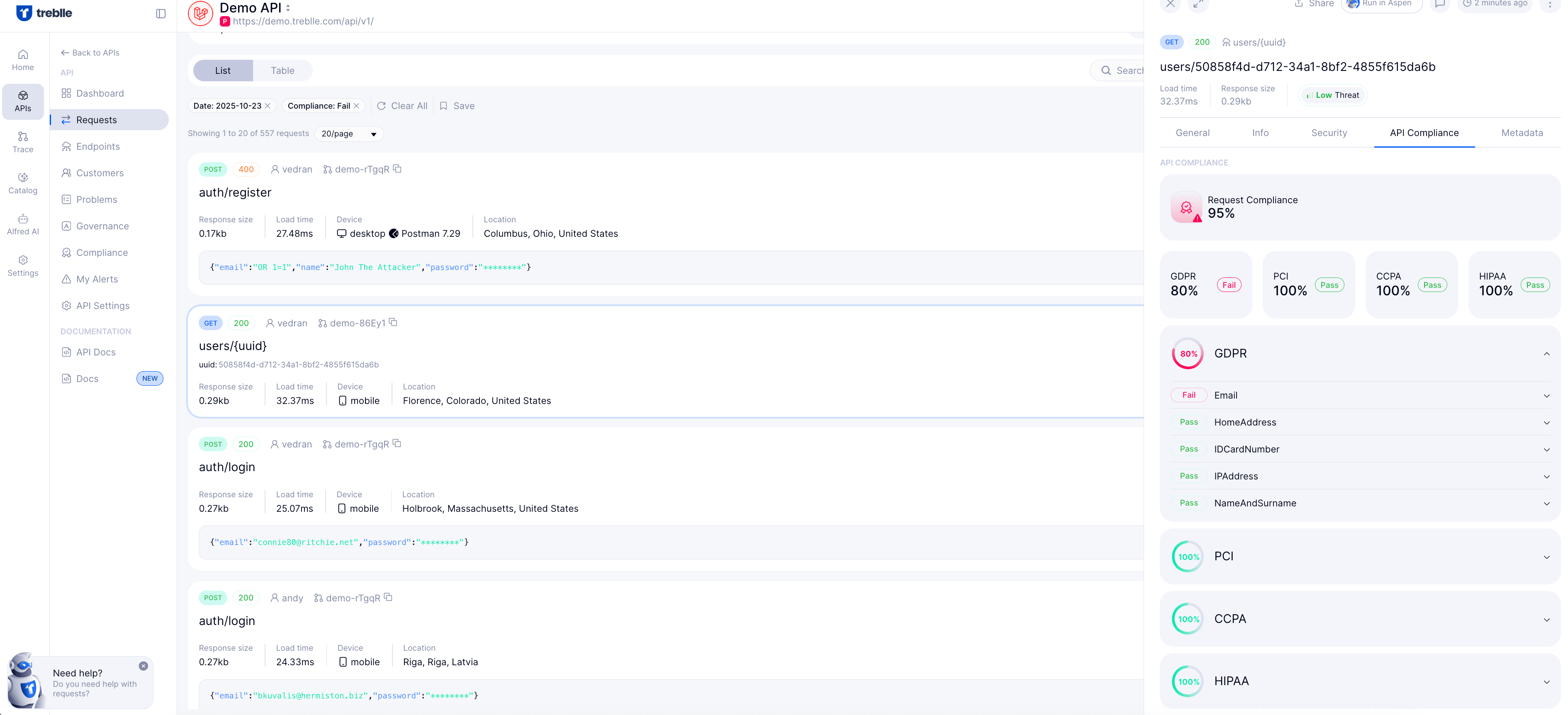
Observability and traceability are essential for identifying issues like cache bypasses and regressions quickly. With Treblle's API Intelligence Platform, you can monitor every request in real-time, providing insights that help you pinpoint exactly where the problems lie. This level of observability means that if a caching strategy isn’t performing as expected, you can catch it fast.
Think of it as having a magnifying glass on your API performance. You’ll be able to see which requests are hitting the cache and which are not, allowing you to optimize your caching layers more effectively. By improving your ability to trace requests, you can ensure that your API remains responsive and reliable, ultimately enhancing user satisfaction.
API caching is an essential tool for optimizing performance and enhancing user experience. By carefully implementing caching strategies and monitoring their effectiveness, you can ensure your API responds quickly while managing backend load efficiently. The balance between data freshness and caching is crucial, so always keep your users' needs in mind.
As you roll out your caching strategy, consider leveraging Treblle's API Intelligence Platform for significant assistance. With real-time analytics and actionable insights, you can continuously refine your approach to caching. This way, you can focus on building exceptional features while ensuring your API remains fast, reliable, and secure. Embrace the power of caching and watch your API soar!
Need real-time insight into how your APIs are used and performing?
Treblle helps you monitor, debug, and optimize every API request.
Explore TreblleAPI caching enhances performance by reducing server load and speeding up response times. It can lead to a significant decrease in operational costs, often cutting backend load and network usage by up to 70%.
Caching can lead to stale data if not managed properly. Implementing validation strategies, such as time-to-live (TTL) settings, helps ensure that users receive up-to-date information while still benefiting from caching efficiency.
Strategies like adaptive caching and content delivery networks (CDNs) are particularly effective during high-traffic events. For example, The Weather Company uses specific caching settings to handle surges in traffic during storms.
By serving cached responses rather than querying the database for every request, API caching can reduce database operations by as much as 60%. This lowers both computation costs and the strain on database resources.
Developers should evaluate factors such as data volatility, access patterns, and the desired freshness of the data. A well-thought-out caching strategy can prevent issues like stale data while maximizing performance gains.
All Systems Operational
Gartner: Magic Quadrant, 2025
Gartner AI API Strategy, 2025
Everest Group: Enterprise App Integration Platforms, 2026


