
api-governance
API Discovery: How to Find Every API in Your Infrastructure

Summarize with





Do you know all the APIs that are in production? And does the number match the one in the documentation?
Our (educated) guess is no and that's the entire point of API discovery: to find all the APIs that are running on your systems so you know what's happening at all times.
Look at the following data points:
The number of API endpoints increases faster than teams can document and manage. This problem (API sprawl) can't be solved by a single project push. It needs constant (continuous) monitoring, observation, and documentation.
This article covers why API inventories degrade, the three mechanisms that actually surface APIs at scale, and what to do with discovery data once you have it.
The conventional API inventory approach has a natural lag: it's updated by people only occasionally and with a delay. But APIs are created and modified continuously by automated systems.
As an example, a developer would add a new endpoint in deployment on a Thursday, but the documentation (usually a sprint) would happen next quarter. So you get a production endpoint with no documentation for a couple of months (or more, because documentation is notoriously "low prio").
In that time, it already served millions of requests, accumulated security debt, and accumulated consumers who depend on it. Now multiply this by thousands of endpoints across hundreds of APIs, which is what regularly happens during M&A, cloud migrations, or general API sprawl.
The result is an API inventory that's missing more and more production endpoints over time.
That's why you need to automate the process so it's continuously updated and has no lag. With Treblle's Auto-Generated OpenAPI Docs, you can capture a continuous current-state view by generating spec documentation from live traffic rather than from developer-maintained source files. Every endpoint that serves a real request becomes visible regardless of whether anyone updated the docs.
Reliable API discovery requires three independent signal sources, because each covers blind spots the others miss. No single source is complete.
Repository scanning reads source code, configuration files, and OpenAPI specs committed to version control to identify API definitions before they reach production. It surfaces the intended API surface:
The advantage of code scanning is timing: it runs before deployment, which means it can inform governance decisions (Is this endpoint following our naming conventions? Does it have authentication declared?) before the API is live. The limitation is completeness: repository scanning only finds what's been committed. Legacy APIs with no surviving source code, APIs deployed from binary artifacts, and APIs inherited through acquisitions lack a scannable repository.
Treblle's API Discovery pulls from GitHub and other code repositories as one of three discovery sources, surfacing API definitions from spec files and code analysis alongside the gateway and traffic layers.
API gateways, service meshes, and load balancers are transit points for API traffic. They know about every route that's been registered with them, regardless of whether documentation exists. Gateway integration pulls the authoritative list of routed endpoints from the infrastructure layer rather than from documentation.
This source is highly reliable for APIs that flow through the gateway. It misses APIs that bypass the gateway entirely: services that communicate directly without routing through a centralized proxy, legacy systems that predate the current gateway infrastructure, and internal APIs deployed on infrastructure the gateway doesn't see. In organizations with multiple cloud environments, different gateways may cover different surfaces, and stitching them together requires active integration with each.
Traffic-based discovery observes what's actually being called, not what's documented, and not what's registered in a gateway, but what real consumers are actually hitting. It surfaces shadow APIs (endpoints receiving traffic that aren't in any registry), zombie APIs (endpoints in registries but receiving no traffic), and undocumented endpoints that have been in production long enough to accumulate consumers.
This is the only discovery source that reveals the ground truth of production usage. A shadow endpoint that exists in neither documentation nor gateway configuration but receives 500 requests per day is invisible to code scanning and gateway integration (but not to attackers). Traffic analysis sees it on the first request.
The tradeoff is timing: traffic-based discovery is reactive. An endpoint becomes visible only after it receives traffic. An endpoint that exists but has no consumers yet won't appear until it does. Combined with code scanning (which catches new endpoints before traffic arrives) and gateway integration (which catches registered routes before they're called), traffic analysis completes the picture.
Treblle's Real-Time Request Explorer provides the traffic layer: every request is captured in full, including the endpoint, method, consumer identity, and response, enabling identification of which endpoints are actively used, which receive traffic despite not appearing in any registry, and which registered routes are never called.
Each source catches what the others miss.
The combination of all three produces a discovery inventory that accurately reflects the current state of the infrastructure.
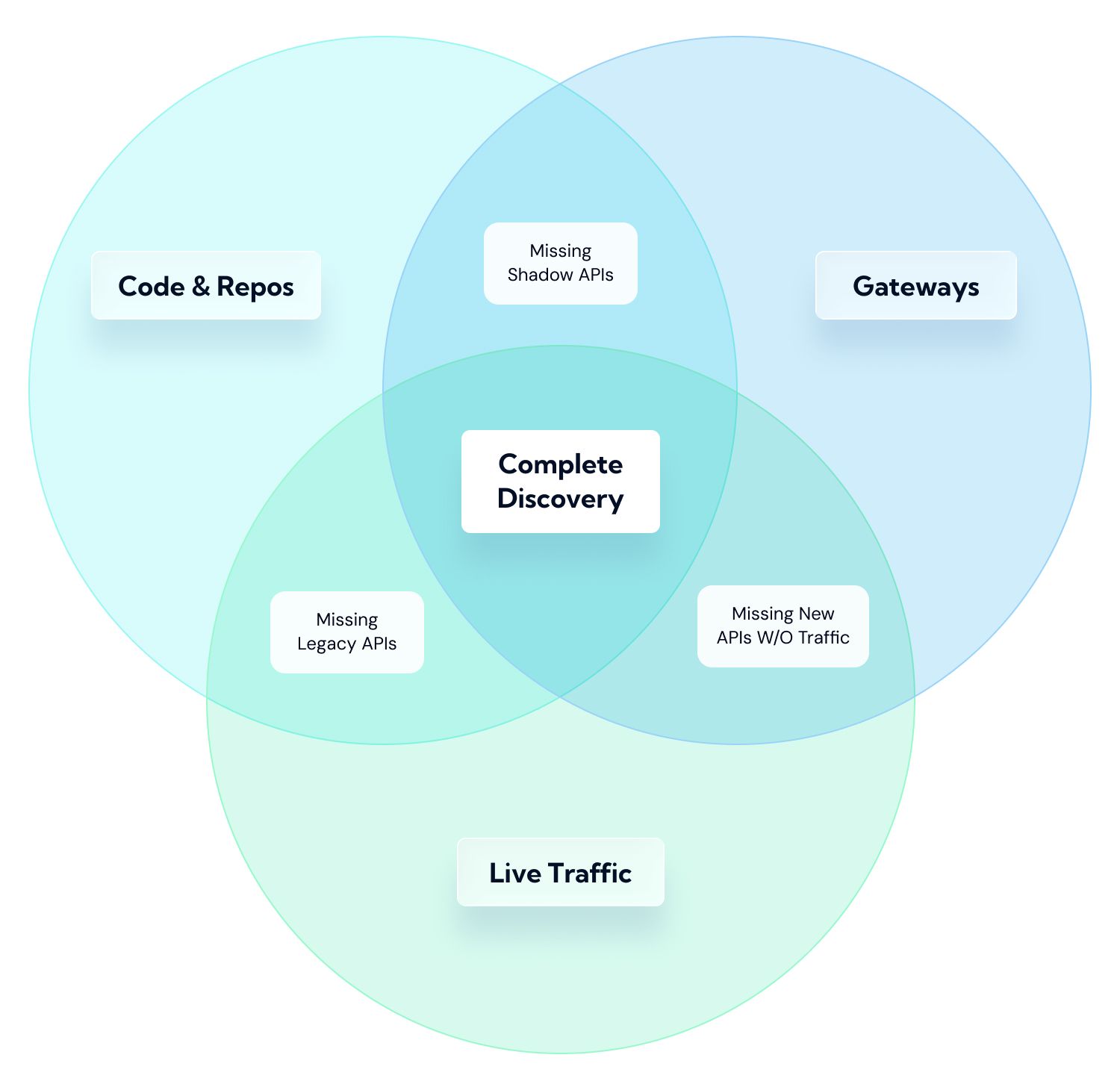
Treblle's API Discovery (Multi-Source) combines GitHub scanning, gateway integrations, and live traffic analysis into a single reconciled view, automatically deduplicating endpoints identified from multiple sources and flagging discrepancies, such as endpoints in the spec not in traffic, endpoints in traffic not in the spec, and routes registered in the gateway with no matching spec entry.
Discovery surfaces two categories of problematic endpoints. They are used as synonyms, but they're different problems with different solutions (and should be approached that way).
Shadow APIs are endpoints that receive traffic but exist outside the documented and governed inventory. They arrived in production through a path that bypassed documentation, governance review, or both. A developer who exposed an internal endpoint without realizing it was externally accessible; a legacy system whose public surface was never fully mapped; a third-party component that made outbound requests to endpoints the integration team didn't know existed. Shadow APIs pose an active risk because they receive requests that aren't subject to the security controls governing the documented surface.
Zombie APIs are endpoints that are documented, registered, or coded but receive no legitimate production traffic. They're the complement of shadow APIs: visible in documentation, invisible in usage. Zombie endpoints exist for many reasons: endpoints built for a use case that never materialized, API versions superseded but not decommissioned, and internal tools built for a team that no longer exists. The zombie endpoint share grew from 24% in 2023 to 35% in 2024. That trajectory of growth is the natural result of the API surface expanding faster than decommissioning practices can keep up with.
The solutions are different. Shadow APIs need to be either brought into governance (documented, reviewed, authenticated, and covered by the standard security controls) or shut down. Zombie APIs need to be either decommissioned (sunset date published, consumers notified if any exist) or re-evaluated for their original purpose. Both require discovery first, but what you do with them once found is opposite: shadow APIs are undocumented and active; zombie APIs are documented and inactive.
Treblle's Authentication Coverage Tracking also plays a role here: when discovery surfaces a shadow API that's processing real traffic, the next question is whether it's authenticated. In Treblle's dataset, 47% of APIs process requests with no authentication. Shadow endpoints are disproportionately likely to be in that 47%. They bypassed the review process that would have caught missing auth requirements before deployment.
A list of endpoints isn't a useful API inventory. To make discovery data actionable, each entry needs metadata that makes it governable.
Ownership is the most critical field. Which team owns this API? Who is the technical contact? Without ownership, an audit finding has nowhere to land and a decommissioning decision has no one to approve it. Discovery data without ownership data results in a list of APIs with no way to address problems.
Environment disambiguates the surface. A production endpoint and a staging endpoint with the same path are different from a governance perspective: different risk profiles, different compliance scopes, and different appropriate access controls. Discovery that conflates environments makes risk assessment impossible.
Category and sensitivity classify what the API does and what data it handles. An API that returns public product listings has a different security posture requirement than an API that returns PII. Category metadata (internal, external, partner) and sensitivity classification (public, internal, confidential, regulated) are what allow governance rules to be applied selectively rather than uniformly.
Discovered-by source. Understanding whether the endpoint appeared in code, gateway, or traffic is useful for reconciliation. An endpoint that appears in traffic but not in code or gateway is a shadow API requiring urgent attention. An endpoint that appears in code but never appears in traffic is a zombie candidate. The source field makes the remediation path visible immediately.
Last-active timestamp separates zombie candidates from genuinely unused-but-valid endpoints. An endpoint built for a quarterly batch process that runs four times per year isn't a zombie; it's working as intended. Last-active data contextualizes the absence of traffic.
Discovery produces data. A catalog makes that data usable by the people who need it: developers integrating with the APIs, security teams assessing the surface, and platform teams managing the portfolio.
The distinction between discovery and catalog matters. Discovery is a continuous process that pulls raw endpoint data from code, gateways, and traffic. An API catalog is a curated, governed registry of that data, enriched with the ownership and metadata described above, normalized to a consistent format, and maintained as the authoritative reference.
Building a catalog from discovery data requires three ongoing operations:
Treblle's API Catalog provides the central registry: discovered endpoints are normalized, tagged with ownership and environment metadata, and surfaced in a searchable interface with consumption tracking, interactive documentation, and AI assistant integration that helps consumers understand how to use the APIs they find.
For organizations building toward a full internal developer portal around their catalog, the API governance framework article covers how catalog data feeds governance, scoring, and standards enforcement across the portfolio.
The discovery problem is harder in multi-cloud and hybrid environments, because the same API surface can span AWS API Gateway, Azure API Management, a Kubernetes ingress, and an on-premises service mesh simultaneously.
Each of these has its own gateway layer, its own traffic logs, and its own configuration format. Discovery tools that integrate only with a single gateway layer produce a partial view, accurate only within that environment but blind to everything outside it.
The practical implication is that cross-environment discovery requires a layer of abstraction above the infrastructure: something that integrates with multiple gateway types and traffic sources and normalizes the output into a unified inventory. Without that normalization layer, teams end up manually reconciling multiple partial inventories, which recreates the same staleness problem that motivated API discovery in the first place.
M&A situations make this concrete: 53% of organizations encounter a critical cybersecurity issue during an M&A transaction, often traced to undocumented APIs or inherited security debt from the acquired entity. The integration period between close and technical integration is the window where the inherited API surface is most dangerous. It exists, it may be publicly accessible, and the acquiring team has no inventory of it. Discovery that can scan an unfamiliar code repository and surface its API surface from traffic and gateway data is the fastest path from "we don't know what they have" to "we have a full inventory with authentication gaps flagged."
The API inventory problem is fundamentally a speed problem. APIs are created, modified, and abandoned at the pace of software development. Any inventory process that depends on manual updates runs at the pace of documentation sprints. Continuous discovery runs at the pace of the infrastructure.
API Discovery (Multi-Source). Surfaces APIs from GitHub repository scanning, gateway integrations, and live traffic analysis in a single reconciled view. Automatically identifies shadow endpoints (traffic without documentation) and zombie endpoints (documentation without traffic), and flags authentication gaps on newly surfaced endpoints.
API Catalog. Centralized registry of all discovered APIs with ownership metadata, environment tags, category classification, and consumption analytics. Provides the governed layer above raw discovery data: enriched, searchable, and connected to interactive documentation and SDK generation.
Auto-Generated OpenAPI Docs. Generates spec documentation from live traffic, catching undocumented endpoints and spec drift automatically. Every endpoint that serves a real request becomes visible in the spec, regardless of whether it was manually documented.
Authentication Coverage Tracking. When discovery surfaces a previously unknown endpoint, Authentication Coverage Tracking immediately reveals whether it's enforcing authentication in practice and identifies the shadow APIs most likely to carry authentication debt from bypassing the governance process.
Real-Time Request Explorer. The traffic source for discovery: every request is captured in full, including the endpoint, consumer identity, and response data. Provides the usage signal that separates active APIs from zombie candidates and flags shadow APIs from the moment their first request arrives.
What is API discovery?
What is the difference between a shadow API and a zombie API?
Why do API inventories go out of date so quickly?
What should an API catalog include?
How does API discovery help with API security?
All Systems Operational
Gartner: Magic Quadrant, 2025
Gartner AI API Strategy, 2025
Everest Group: Enterprise App Integration Platforms, 2026


